
What Is Search Engine Work?
A search engine is a software system designed to search for information on the World Wide Web.
(1) Crawling (2) Indexing (3) Search Results
Crawling:
- Search engines use automated programs called crawlers or spiders to browse the web and discover new or updated content.
- These crawlers start by visiting a list of known web pages or by following links from one page to another.
- The crawler collects information about the pages it visits, such as the text content, images, and metadata.
Indexing:
- After crawling, the search engine creates an index, which is essentially a large database of the collected information.
- The index is organized in a way that facilitates quick and efficient retrieval of relevant data when a user performs a search.
Ranking Algorithm:
- When a user enters a query into the search engine, the search algorithm determines which pages in the index are most relevant to the query.
- The ranking algorithm considers various factors to determine relevance, such as the presence of search terms in the content, the quality and quantity of links pointing to a page, and other relevance signals.
Search Query Processing:
- The user’s query goes through a process called query processing, where the search engine identifies relevant documents from its index.
- Algorithms analyze the query to understand the user’s intent and provide the most accurate and useful results.
Search Results Page:
- The search engine then displays a list of results on the search results page (SERP) based on the ranking of pages.
- Results typically include titles, snippets (brief descriptions), and URLs to help users decide which pages to click.
How to Check Your Website is Index
- Google Search:
- Go to the Google search bar.
- Enter
site:yourdomain.com(replace “yourdomain.com” with your actual domain name) and press Enter. - This search operator (
site:) will show you all the pages from your domain that Google has indexed. - Example:
site:example.com - If your website is indexed, you will see a list of pages from your domain in the search results.
- Google Search Console:
- If you haven’t already, sign up for Google Search Console (previously known as Google Webmaster Tools) and verify ownership of your website.
- Once verified, log in to Google Search Console.
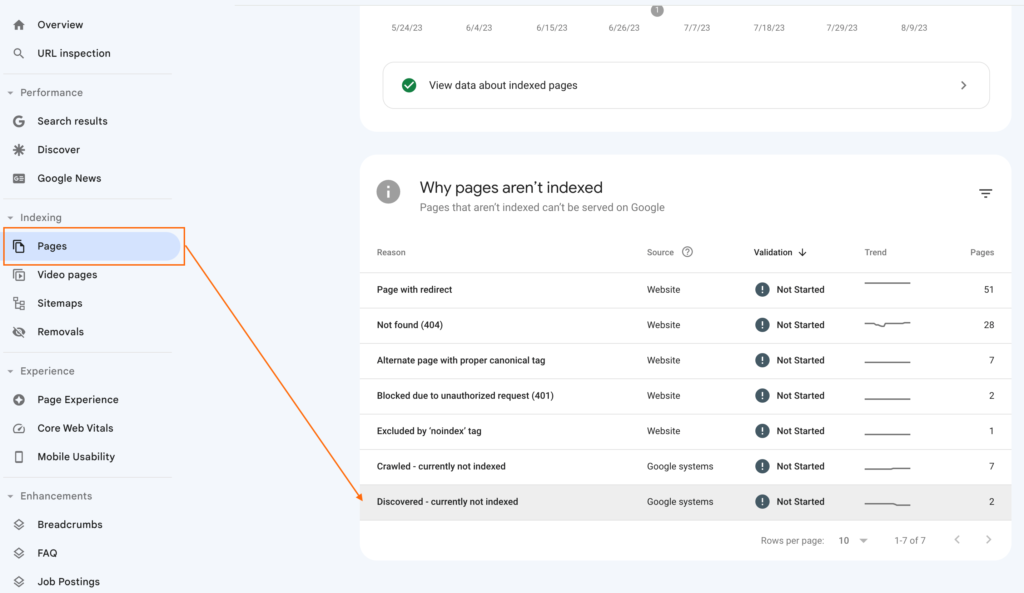
- In the left-hand menu, click on “Index” and then select “Coverage.” This section will provide information on the indexing status of your pages.
- Google Search Console will show you details such as the number of valid, indexed pages, as well as any issues preventing certain pages from being indexed

Common Technical Indexing Problem
- The page isn’t crawlable and/or doesn’t return a 200 status code: Check robots.txt file, improve server responses, and fix crawlability issues.
Robots meta directive doesn’t allow indexing. :
Check the
<meta name="robots">tag on the page in question. Ensure that it doesn’t contain the “noindex” directive. If it does, remove or modify the directive to allow indexing.Review the webpage’s source code for any other potential directives that might be blocking indexing. Look for meta tags, headers, or other HTML elements that could be preventing search engine bots from indexing the page.
Ensure that there are no conflicting directives in the robots.txt file. Open your website’s robots.txt file and verify that it doesn’t contain a “disallow” rule for the specific page or directory you want to be indexed. If it does, modify the robots.txt file to allow indexing of the desired content.
Consider using the “Fetch as Google” tool in Google Search Console (if applicable) to test how Googlebot sees your page. This will help identify any issues or directives that are preventing indexing.
If the page is behind a login or requires authentication, ensure that search engine bots can access and crawl the content. Consider implementing proper authentication mechanisms or exclusions in your robots.txt file.
Monitor the server response codes for the page in question. If the page returns any non-200 HTTP status codes, such as 404 (Not Found) or 500 (Internal Server Error), investigate and resolve these issues, as they can affect indexing.
Page is blocked by robots.txt.:
Verify the robots.txt file: Double-check the robots.txt file on your website to ensure that it is correctly configured. Look for any specific instructions that may be blocking the page in question. The robots.txt file should be accessible at the root level of your website (e.g., www.topsubmissionsites.com/robots.txt).
Allow indexing: If you want the blocked page to be indexed by search engines, modify the robots.txt file to remove the disallow rule for that particular URL or directory. Change the rule from “Disallow: /page-url” to “Allow: /page-url” to explicitly allow indexing.
Test with robots.txt tester tools: Utilize online robots.txt tester tools (such as Google’s Robots.txt Tester in Google Search Console) to validate and troubleshoot your robots.txt file. These tools can help you identify any syntax errors or misconfigurations.
Check for server-side issues: Ensure that the page in question is accessible and functioning properly from a technical standpoint. If there are any server-side issues causing the page to be unavailable, resolve them accordingly.
Indexing directives: Review the HTML source code of the page for indexing directives such as meta tags or header declarations that may be conflicting with the robots.txt instructions. Remove or modify any “noindex” directives if you want the page to be indexed.
Fetch as Google: If the page is not blocked by robots.txt but still not being indexed, use the “Fetch as Google” tool in Google Search Console (if available) to check how Googlebot specifically sees the page. This will help identify any issues that may be preventing indexing.
Page isn’t listed in the sitemap file.:
Generate an updated sitemap: Create or update your website’s sitemap file to include the missing page. A sitemap is an XML file that lists all the important pages on your website. There are various tools and plugins available to generate sitemaps automatically, or you can create one manually.
Submit the sitemap to search engines: Once you have the updated sitemap file, submit it to search engines like Google, Bing, or Yahoo. Most search engines provide webmaster tools or consoles where you can manage your sitemap submissions. This will help search engines discover and crawl the added page.
Verify the sitemap’s syntax: Ensure that your sitemap file follows the proper syntax defined by the search engines. Invalid or malformed sitemaps may cause issues in indexing. You can use online XML validators to check the syntax of your sitemap and make any necessary corrections.
Check crawlability of the page: Verify that the missing page is crawlable by search engine bots. Check for any directives like “noindex” or “nofollow” that may be preventing search engines from indexing the page. Additionally, make sure there are no technical issues like server errors or redirects that hinder search engine bots from accessing the page.
Internal linking: Ensure that the missing page is properly linked within your website’s internal structure. Internal links play a crucial role in helping search engines discover and index your website’s pages. Add relevant links to the missing page from other pages on your site, especially from high-authority and frequently crawled pages.
Monitor indexation: Keep an eye on search engine indexation of your website over time. Regularly check the search engine results pages (SERPs) to see if the missing page has been indexed after making the above changes. If the page still doesn’t appear in the index, recheck the sitemap and page settings for any potential issues.
Duplicate content issues.
Identify duplicate content: Use specialized tools like Screaming Frog or Copyscape to scan your website and identify instances of duplicate content. These tools can help you pinpoint exact matches or near-duplicates of your web pages.
Determine the source: Once you’ve identified the duplicate content, determine the original or preferred version of the page. This is the version you want search engines to index and display in their results.
Choose a solution approach: There are a few approaches you can take to resolve duplicate content issues:
Remove duplicate content: If the duplicate content is unnecessary or low-quality, consider removing it from your website. You can delete the duplicate pages or combine them into a single, consolidated page.
Use 301 redirects: If the duplicate content serves a legitimate purpose or cannot be removed, use 301 redirects to redirect search engines and users to the preferred version of the page. The redirect tells search engines that the original page is the authoritative one, consolidating ranking signals and avoiding indexing of duplicate versions.
Canonical tags: Implement canonical tags (rel=”canonical”) in the HTML header of duplicate pages, specifying the preferred version of the content. This tag helps search engines understand which page to index and rank, consolidating the SEO value of duplicate pages into a single version.
Noindex tags: If the duplicate content is present on pages that you don’t want search engines to index, use the noindex meta tag (meta robots tag) or an X-Robots-Tag HTTP header to instruct search engines not to index those pages.
Update internal links: Once you’ve resolved the duplicate content issue, update any internal links on your website to point to the preferred version of the page. This ensures that users and search engines are directed to the correct URL.
External content duplication: If your content is being duplicated on external websites without permission, you can reach out to the site owners and request them to remove or properly attribute the content. If necessary, you can also file a DMCA complaint with search engines to report copyright infringement.
What is Canonicalization?
Canonicalization is a process in web development and search engine optimization (SEO) that involves standardizing and specifying the preferred version of a URL when there are multiple URLs that could lead to the same content. The goal is to consolidate the indexing signals (such as link equity and content relevance) for a particular piece of content under a single, canonical URL.
Understanding Canonicalization:
1. Why Does Canonicalization Matter?
- Duplicate Content Issues: When search engines encounter multiple URLs with identical or very similar content, they may struggle to determine which version to index and display in search results. This can lead to issues with ranking and the overall user experience.
- Link Equity Distribution: Canonicalization helps consolidate link signals (link equity) that point to different versions of the same content, preventing dilution of SEO value across multiple URLs.
2. Canonical URL:
- The canonical URL is the preferred and authoritative version of a page that search engines should consider when indexing content. It is specified using the
<link>tag with therel="canonical"attribute in the HTML<head>section.
<link rel="canonical" href="https://www.example.com/canonical-url">
- This tag indicates to search engines that the specified URL is the primary version and should be used for indexing and ranking purposes.
3. Common Scenarios Requiring Canonicalization:
- WWW vs. Non-WWW: If your site is accessible with both www and non-www URLs, search engines might treat them as separate pages. Canonicalization helps specify the preferred version.
- HTTP vs. HTTPS: Similar to www vs. non-www, canonicalization can resolve issues related to different protocols (HTTP and HTTPS) serving the same content.
- URL Parameters: Dynamic URLs with parameters can create multiple versions of the same content. Canonicalization can consolidate these variations.
- Trailing Slashes: URLs with and without trailing slashes (e.g., /page/ vs. /page) might be treated as distinct by search engines. Canonicalization helps unify them.

Excellent blog here Also your website loads up very fast What web host are you using Can I get your affiliate link to your host I wish my web site loaded up as quickly as yours lol
Hostinger